Предложение SQL GROUP BY группирует строки, возвращаемые запросом, в группы в Python.
Введение в группу Django
Обычно вы используете агрегатные функции, такие как count, min, max, avg и sum с предложением GROUP BY, чтобы вернуть агрегированное значение для каждой группы. Рассмотрим, как использовать Django Group By с агрегатными функциями для расчета агрегации для групп.
Вот базовое использование предложения GROUP BY в операторе SELECT:
SELECT column_1, AGGREGATE(column_2) FROM table_name GROUP BY column1;
В Django вы можете использовать метод annotate() с values(), чтобы применить агрегацию к группам следующим образом:
(Entity.objects
.values('column_2')
.annotate(value=AGGREGATE('column_1'))
)
В этом синтаксисе;
- values(‘column_2’) – передайте столбец, который вы хотите сгруппировать, в метод values().
- annotate(value=AGGREGATE(‘column_1’)) – укажите, что следует агрегировать в методе annotate().
Обратите внимание, что порядок вызова values() и annotates() имеет значение. Если вы не вызовете метод values() первым, а annotate() вторым, выражение не даст агрегированных результатов.
Примеры с Django Group By
Для демонстрации мы будем использовать модели Employee и Department из приложения HR. Модели Emloyee и Department сопоставляются с таблицами hr_employee и hr_department в базе данных:
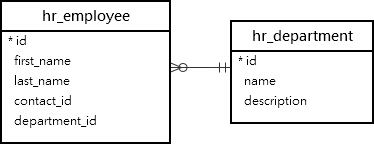
1) Пример Group By с подсчетом
В следующем примере используются методы values() и annotate() для получения количества сотрудников по отделам:
>>>(Employee.objects
... .values('department')
... .annotate(head_count=Count('department'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001492s [Database: default]
<QuerySet [{'department': 1, 'head_count': 30}, {'department': 2, 'head_count': 40}, {'department': 3, 'head_count': 28}, {'department': 4, 'head_count': 29}, {'department': 5, 'head_count': 29}, {'department': 6, 'head_count': 30}, {'department': 7, 'head_count': 34}]>
Как это работает.
- Сначала сгруппируем сотрудников по отделам, используя метод values():
values('department')
- Во-вторых, примените Count() к каждой группе:
annotate(head_count=Count('department'))
- В-третьих, отсортируйте объекты в QuerySet по отделу:
order_by('department')
За кулисами Django выполняет оператор SELECT с предложением GROUP BY:
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
2) Пример Django Group By с суммой
Аналогичным образом можно использовать агрегат Sum() для расчета общей заработной платы сотрудников в каждом отделе:
>>>(Employee.objects
... .values('department')
... .annotate(total_salary=Sum('salary'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
SUM("hr_employee"."salary") AS "total_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.000927s [Database: default]
<QuerySet [{'department': 1, 'total_salary': Decimal('3615341.00')}, {'department': 2, 'total_salary': Decimal('5141611.00')}, {'department': 3, 'total_salary': Decimal('3728988.00')}, {'department': 4, 'total_salary': Decimal('3955669.00')}, {'department': 5, 'total_salary': Decimal('4385784.00')}, {'department': 6, 'total_salary': Decimal('4735927.00')}, {'department': 7, 'total_salary': Decimal('4598788.00')}]>
3) Пример Django group by с минимальным, максимальным и средним значением
В следующем примере к группам применяется несколько агрегатных функций для получения самой низкой, средней и самой высокой зарплаты сотрудников в каждом отделе:
>>>(Employee.objects
... .values('department')
... .annotate(
... min_salary=Min('salary'),
... max_salary=Max('salary'),
... avg_salary=Avg('salary')
... )
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
MIN("hr_employee"."salary") AS "min_salary",
MAX("hr_employee"."salary") AS "max_salary",
AVG("hr_employee"."salary") AS "avg_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001670s [Database: default]
<QuerySet [{'department': 1, 'min_salary': Decimal('45427.00'), 'max_salary': Decimal('149830.00'), 'avg_salary': Decimal('120511.366666666667')}, {'department':
2, 'min_salary': Decimal('46637.00'), 'max_salary': Decimal('243462.00'), 'avg_salary': Decimal('128540.275000000000')}, {'department': 3, 'min_salary': Decimal('40762.00'), 'max_salary': Decimal('248265.00'), 'avg_salary': Decimal('133178.142857142857')}, {'department': 4, 'min_salary': Decimal('43000.00'), 'max_salary':
Decimal('238016.00'), 'avg_salary': Decimal('136402.379310344828')}, {'department': 5, 'min_salary': Decimal('42080.00'), 'max_salary': Decimal('246403.00'), 'avg_salary': Decimal('151233.931034482759')}, {'department': 6, 'min_salary': Decimal('58356.00'), 'max_salary': Decimal('248312.00'), 'avg_salary': Decimal('157864.233333333333')}, {'department': 7, 'min_salary': Decimal('40543.00'), 'max_salary': Decimal('238892.00'), 'avg_salary': Decimal('135258.470588235294')}]>
4) Пример с объединением
В следующем примере методы values() и annotate() используются для получения количества сотрудников в отделе:
>>>(Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
LIMIT 21
Execution time: 0.001953s [Database: default]
<QuerySet [{'name': 'Marketing', 'head_count': 28}, {'name': 'Finance', 'head_count': 29}, {'name': 'SCM', 'head_count': 29}, {'name': 'GA', 'head_count': 30}, {'name': 'Sales', 'head_count': 40}, {'name': 'IT', 'head_count': 30}, {'name': 'HR', 'head_count': 34}]>
Как это работает.
- values(‘name’) – группирует отделы по названию.
- annotate(headcount=Count(’employee’)) – подсчитывает количество сотрудников в каждом отделе.
В фоновом режиме Django использует LEFT JOIN для объединения таблицы hr_department с таблицей hr_employee и применяет функцию COUNT() к каждой группе.
Django GROUP BY с HAVING
Чтобы применить условие к группам, используйте метод filter(). Например, следующий пример использует метод filter() для получения отдела с количеством сотрудников более 30:
>>>(Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... .filter(head_count__gt=30)
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30
LIMIT 21
Execution time: 0.002893s [Database: default]
<QuerySet [{'name': 'Sales', 'head_count': 40}, {'name': 'HR', 'head_count': 34}]>
За кулисами Django использует предложение HAVING для фильтрации группы на основе условия, которое мы передаем методу filter():
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30