В этом руководстве вы узнаете, как использовать модуль threading в Python для разработки многопоточных программ и приложений.
Однопоточные приложения
Начнем с простой программы:
from time import sleep, perf_counter
def task():
print('Starting a task...')
sleep(1)
print('done')
start_time = perf_counter()
task()
task()
end_time = perf_counter()
print(f'It took {end_time- start_time: 0.2f} second(s) to complete.')
Как это работает.
- Сначала импортируйте функции Sleep() и perf_counter() из модуля time:
from time import sleep, perf_counter
- Во-вторых, определите функцию, выполнение которой занимает одну секунду:
def task():
print('Starting a task...')
sleep(1)
print('done')
- В-третьих, получите значение счетчика производительности, вызвав функцию perf_counter():
start_time = perf_counter()
- В-четвертых, дважды вызовите функцию Task():
task() task()
- В-пятых, получите значение счетчика производительности, вызвав функцию perf_counter():
end_time = perf_counter()
- Наконец, выведите время, необходимое для двойного выполнения функции Task():
print(f'It took {end_time- start_time: 0.2f} second(s) to complete.')
Вот результат:
Starting a task... done Starting a task... done It took 2.00 second(s) to complete.
Как и следовало ожидать, выполнение программы занимает около двух секунд. Если вы вызовете функцию Task() 10 раз, ее выполнение займет около 10 секунд.
На следующей диаграмме показано, как работает программа:
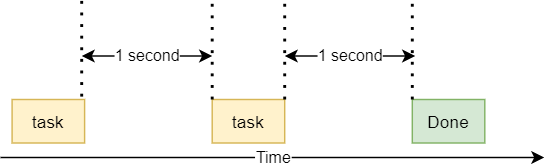
Сначала функция Task() выполняется и приостанавливается на одну секунду. Затем она выполняется второй раз и также приостанавливается еще на секунду. Наконец, программа завершается.
Когда функция Task() вызывает функцию Sleep(), процессор простаивает. Другими словами, ЦП ничего не делает, что неэффективно с точки зрения использования ресурсов.
В этой программе есть один процесс с одним потоком, который называется основным потоком. Поскольку программа имеет только один поток, ее называют однопоточной программой.
Разработка многопоточной программы с помощью модуля threading
Чтобы создать многопоточную программу, вам необходимо использовать модуль threading в Python.
- Сначала импортируйте класс Thread из модуля threading:
from threading import Thread
- Во-вторых, создайте новый поток, создав экземпляр класса Thread:
new_thread = Thread(target=fn,args=args_tuple)
Thread() принимает множество параметров. Основные из них:
- target: указывает функцию(fn), которую нужно запустить в новом потоке.
- args: указывает аргументы функции(fn). Аргумент args представляет собой кортеж.
- В-третьих, запустите поток, вызвав метод start() экземпляра Thread:
new_thread.start()
Если вы хотите дождаться завершения потока в основном потоке, вы можете вызвать метод join():
new_thread.join()
Вызвав метод join(), основной поток будет ждать завершения дочернего потока, прежде чем он завершится.
Следующая программа иллюстрирует, как использовать модуль threading:
from time import sleep, perf_counter
from threading import Thread
def task():
print('Starting a task...')
sleep(1)
print('done')
start_time = perf_counter()
# create two new threads
t1 = Thread(target=task)
t2 = Thread(target=task)
# start the threads
t1.start()
t2.start()
# wait for the threads to complete
t1.join()
t2.join()
end_time = perf_counter()
print(f'It took {end_time- start_time: 0.2f} second(s) to complete.')
Как это работает:
- Сначала создайте две новые темы:
t1 = Thread(target=task) t2 = Thread(target=task)
- Во-вторых, запустите оба потока, вызвав метод start():
t1.start() t2.start()
- В-третьих, дождитесь завершения обоих потоков:
t1.join() t2.join()
- Наконец, покажите время выполнения:
print(f'It took {end_time- start_time: 0.2f} second(s) to complete.')
Выход:
Starting a task... Starting a task... done done It took 1.00 second(s) to complete.
Когда программа выполняется, она будет иметь три потока: основной поток и два других дочерних потока.
Как ясно видно из выходных данных, выполнение программы заняло одну секунду вместо двух.
На следующей диаграмме показано, как выполняются потоки:
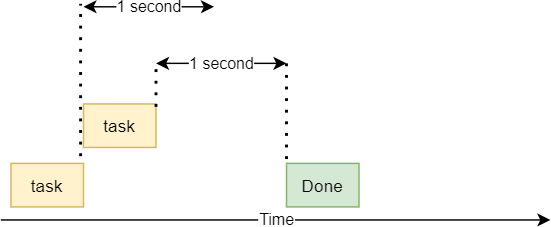
Передача аргументов в потоки
Следующая программа показывает, как передавать аргументы функции, назначенной потоку:
from time import sleep, perf_counter
from threading import Thread
def task(id):
print(f'Starting the task {id}...')
sleep(1)
print(f'The task {id} completed')
start_time = perf_counter()
# create and start 10 threads
threads = []
for n in range(1, 11):
t = Thread(target=task, args=(n,))
threads.append(t)
t.start()
# wait for the threads to complete
for t in threads:
t.join()
end_time = perf_counter()
print(f'It took {end_time- start_time: 0.2f} second(s) to complete.')
Как это работает.
- Сначала определите функцию Task(), которая принимает аргумент:
def task(id):
print(f'Starting the task {id}...')
sleep(1)
print(f'The task {id} completed')
- Во-вторых, создайте 10 новых потоков и передайте каждому идентификатор. Список потоков используется для отслеживания всех вновь созданных потоков:
threads = []
for n in range(1, 11):
t = Thread(target=task, args=(n,))
threads.append(t)
t.start()
Обратите внимание: если вы вызываете метод join() внутри цикла, программа будет ждать завершения первого потока, прежде чем запускать следующий.
- В-третьих, дождитесь завершения всех потоков, вызвав метод join():
for t in threads:
t.join()
Ниже показан вывод программы:
Starting the task 1... Starting the task 2... Starting the task 3... Starting the task 4... Starting the task 5... Starting the task 6... Starting the task 7... Starting the task 8... Starting the task 9... Starting the task 10... The task 10 completed The task 8 completed The task 1 completed The task 6 completed The task 7 completed The task 9 completed The task 3 completed The task 4 completed The task 2 completed The task 5 completed It took 1.02 second(s) to complete.
Это заняло всего 1,05 секунды.
Обратите внимание, что программа не выполняет потоки в порядке от 1 до 10.
Когда использовать многопоточность в Python
Как было показано в руководстве по процессам и потокам, существует два основных типа задач:
- Задачи, связанные с вводом-выводом — время, затрачиваемое на ввод-вывод, значительно больше, чем время, затрачиваемое на вычисления.
- Задачи, связанные с процессором — время, затрачиваемое на вычисления, значительно превышает время ожидания ввода-вывода.
Потоки Python оптимизированы для задач, связанных с вводом-выводом. Например, запрос удаленных ресурсов, подключение сервера базы данных или чтение и запись файлов.
Практический пример работы с потоками Python
Предположим, у вас есть список текстовых файлов в папке, например C:/temp/. И вы хотите заменить текст на новый во всех файлах.
Следующая однопоточная программа показывает, как заменить подстроку новой в текстовых файлах:
from time import perf_counter
def replace(filename, substr, new_substr):
print(f'Processing the file {filename}')
# get the contents of the file
with open(filename, 'r') as f:
content = f.read()
# replace the substr by new_substr
content = content.replace(substr, new_substr)
# write data into the file
with open(filename, 'w') as f:
f.write(content)
def main():
filenames = [
'c:/temp/test1.txt',
'c:/temp/test2.txt',
'c:/temp/test3.txt',
'c:/temp/test4.txt',
'c:/temp/test5.txt',
'c:/temp/test6.txt',
'c:/temp/test7.txt',
'c:/temp/test8.txt',
'c:/temp/test9.txt',
'c:/temp/test10.txt',
]
for filename in filenames:
replace(filename, 'ids', 'id')
if __name__ == "__main__":
start_time = perf_counter()
main()
end_time = perf_counter()
print(f'It took {end_time- start_time :0.2f} second(s) to complete.')
Выход:
It took 0.16 second(s) to complete.
Следующая программа имеет ту же функциональность. Однако вместо этого она использует несколько потоков:
from threading import Thread
from time import perf_counter
def replace(filename, substr, new_substr):
print(f'Processing the file {filename}')
# get the contents of the file
with open(filename, 'r') as f:
content = f.read()
# replace the substr by new_substr
content = content.replace(substr, new_substr)
# write data into the file
with open(filename, 'w') as f:
f.write(content)
def main():
filenames = [
'c:/temp/test1.txt',
'c:/temp/test2.txt',
'c:/temp/test3.txt',
'c:/temp/test4.txt',
'c:/temp/test5.txt',
'c:/temp/test6.txt',
'c:/temp/test7.txt',
'c:/temp/test8.txt',
'c:/temp/test9.txt',
'c:/temp/test10.txt',
]
# create threads
threads = [Thread(target=replace, args=(filename, 'id', 'ids'))
for filename in filenames]
# start the threads
for thread in threads:
thread.start()
# wait for the threads to complete
for thread in threads:
thread.join()
if __name__ == "__main__":
start_time = perf_counter()
main()
end_time = perf_counter()
print(f'It took {end_time- start_time :0.2f} second(s) to complete.')
Выход:
Processing the file c:/temp/test1.txt Processing the file c:/temp/test2.txt Processing the file c:/temp/test3.txt Processing the file c:/temp/test4.txt Processing the file c:/temp/test5.txt Processing the file c:/temp/test6.txt Processing the file c:/temp/test7.txt Processing the file c:/temp/test8.txt Processing the file c:/temp/test9.txt Processing the file c:/temp/test10.txt It took 0.02 second(s) to complete.
Как ясно видно из вывода, многопоточная программа работает намного быстрее.